1. C语言中的 sizeof 问题(1)类型转换的问题
#include <stdio.h>
#define NUM (sizeof(arr) / sizeof(arr[0]))
int arr[] = {
1,
2,
3,
4,
5,
6,
7 };
int main()
{
int i;
for( i = -
1; i <= ( NUM -
2 ); i++)
{
printf(
" %d\n ",arr[i+
1]);
}
return 0;
}
输出的结果是空的!解释:我们要知道的是:sizeof 返回的是一个unsinged int的值!那么在for循环的时候,i = -1就会向后面转型,将其值转化为sizeof的值,那么我们很清楚,-1转化的sizeof的值是很大的一个正整数!那么很显然就直接不符合i <= ( NUM - 2 )的条件了,所以就不会输出!!!(2)sizeof是操作符
#include <stdio.h>
int main()
{
int i;
i =
10;
printf(
" i : %d\n ",i);
printf(
" sizeof(i++) is: %d\n ",
sizeof(i++));
printf(
" i : %d\n ",i);
return 0;
}
结果是 i : 10 sizeof(i++) is: 4 i : 10为什么第三个还是输出10呢?!解释:解决这个问题就是要理解编译器编译原理。 我们要知道sizeof仅仅是一个操作符而已并不是函数,sizeof要做的仅仅是获得i++的字节数,那么所以在编译的时候就直接用4代替了i++了,反正编译器知道结果都是一样,所以最终i++并没有执行!2. 非C++内建型别 A 和 B,在哪几种情况下B能隐式转化为A?[C++中等]答:
a.
class B :
public A { ……}
// B公有继承自A,可以是间接继承的 b.
class B {
operator A( ); }
// B实现了隐式转化为A的转化 c.
class A { A(
const B& ); }
// A实现了non-explicit的参数为B(可以有其他带默认值的参数)构造函数 d. A&
operator= (
const A& );
// 赋值操作,虽不是正宗的隐式类型转换,但也可以勉强算一个
3. C++对象声明的陷阱
struct Test
{
Test(
int ) {}
Test() {}
void fun() {}
};
void main(
void )
{
Test a(
1);
a.fun();
Test b();
// 这儿的问题,C++中默认构造函数生成实例不用加括号,如果加上括号这儿就像定义了一个函数 b.fun();
}
4. 以下代码有什么问题?[C++易]cout << (true?1:"1") << endl;这儿条件操作符中的前后的类型要一致一个条件操作符是下面这样的形式:exp1 ? exp2 : exp3表达式exp1总是会被求值。exp2和exp3是否被执行依赖于exp1的值,如果exp1为真则exp2会被求值,否则exp3被求值。Side Effect:在执行exp2或者exp3之前,exp1的所有side effect必须全部求值或者更新完成,因为条件操作符的第一个操作数求值之后就是一个sequence point。如果exp2和exp3都有side effect,那么只有一个会被求值。返回类型:条件操作符的返回类型取决于exp2和exp3类型,编译器会检查exp2(可能是一个class type)能否转换为exp3或者exp3能否转换为exp2,如果两个都不满足,编译器就会抛出一个错误。5. C++中的空类,默认产生哪些类成员函数?[C++易]答:
class Empty
{
public:
Empty();
// 缺省构造函数 Empty(
const Empty& );
// 拷贝构造函数 ~Empty();
// 析构函数 Empty&
operator=(
const Empty& );
// 赋值运算符 Empty*
operator&();
// 取址运算符 const Empty*
operator&()
const;
// 取址运算符 const };
6. 转换为引用类型:浮点数内存表示
float a =
1.0f;
cout << (
int)a << endl;
cout << (
int&)a << endl;
cout << boolalpha << ( (
int)a == (
int&)a ) << endl;
float b =
0.0f;
cout << (
int)b << endl;
cout << (
int&)b << endl;
cout << boolalpha << ( (
int)b == (
int&)b ) << endl;
问:上述代码的输出结果是什么?这种转换为引用类型的情况的确比较少见,但有些时候必须用它!(EC++ 3rd)中讲解copy assignment operator时就提到过一种必须用它的情形。大概需要记住的就是,转向普通类型,则返回的其实是一个为你新创建的临时对象;而转换为引用类型,则返回的其实是你要转换的那个对象本身,只是reinterpret了一下而已,原来的对象内容也没改变。"转换为引用类型"操作的本质: "(int&)a 等价于 *(int*)(&a); 就是把原始a 的内存里面数据按照整形输出。因此不等价于(int)a;"另外的解释:(int&)a 不经过转换, 直接得到a在内存单元的值,并将其转换成整数输出。
7. C语言字符串与字符数组
以下输出语句分别输出什么?[C易]
char str1[] =
" abc ";
char str2[] =
" abc ";
const char str3[] =
" abc ";
const char str4[] =
" abc ";
const char* str5 =
" abc ";
const char* str6 =
" abc ";
char* str7 =
" abc ";
char* str8 =
" abc ";
char* str9 =
" efg ";
char* str0 =
" efg ";
cout<<
" str1= "<<(
void*)str1<<
" "<<
" str2= "<<(
void*)str2<<
" ";
cout << boolalpha << ( str1==str2 ) << endl;
// 输出什么? cout<<
" str3= "<<(
void*)str3<<
" "<<
" str4= "<<(
void*)str4<<
" ";
cout << boolalpha << ( str3==str4 ) << endl;
// 输出什么? cout<<
" str5= "<<(
void*)str5<<
" "<<
" str6= "<<(
void*)str6<<
" ";
cout << boolalpha << ( str5==str6 ) << endl;
// 输出什 cout<<
" str7= "<<(
void*)str7<<
" "<<
" str8= "<<(
void*)str8<<
" ";
cout << boolalpha << ( str7==str8 ) << endl;
// 输出什 cout<<
" str9= "<<(
void*)str9<<
" "<<
" str0= "<<(
void*)str0<<
" ";
cout << boolalpha << ( str9==str0 ) << endl;
// 输出什 在linux平台下的结果是:
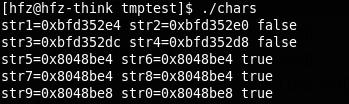
这个应该比较好理解,数组是要分配空间的,因为它的内容是可以改变的,所以地址是不同的。而字符串是不允许改变的,相同的字符串应该是统一存放的。
8. 其他类型到bool的隐式转换
下面的代码输出是什么?
#include <iostream>
#include <
string>
using namespace std ;
void a(
bool input) {
cout <<
" I amd first " <<endl;
cout <<input <<endl ;
}
void a(
const string &input) {
cout<<
" I amd second " <<endl ;
cout<<input <<endl ;
}
int main(
int argc,
char **argv)
{
a(
" str ") ;
// 是调用第二个a函数吗? a(
string(
" str ")) ;
return 0 ;
}
输出结果竟然是:
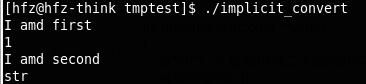
char*类型的"str"居然被隐式转化成了bool类型
然后做实验验证一下:
#include <
string>
using namespace std;
int main(
int argc,
const char *argv [])
{
int a =
1;
char *b=
" wo ";
float c =
1.1;
bool x ;
x = a;
x = b;
x = c;
return 0;
}
int,char*,float确实都可以隐式转化成bool而不会有任何警告,导致出现问题很不容易发现,这里在重载函数的时候确实需要万分注意。
9. 堆排序在大数据中的应用
堆排序的时间复杂度为O(nlogn),最坏的情况也是这个时间复杂度,空间复杂度是O(1)。但是堆排序是不稳定的!
在面试过程中,很多时候都会用到堆排序,比如下面的题目都是堆排序的典型题目:
1.给你100w个数据求最大的10个元素。这个时候我们可以使用小顶堆!这个是为什么呢!
2.给你100w个数据求最小的10个元素。这个时候我们可以使用大顶堆!这个是为什么呢!
相信会有很多同学会问出上面的两个疑问,答案其实很简单,在求最大的元素的时候,我们建立一个有10个元素的小顶堆,那么堆顶元素肯定是最小的,然后拿剩余的元素和堆顶进行比较,如果比堆顶大,就替换这个元素,然后调整堆,调整完之后堆顶依然是10个元素中最小的,依次比较剩余的元素。
堆排序与直接插入排序的区别
直接选择排序中,为了从R[1..n]中选出关键字最小的记录,必须进行n-1次比较,然后在R[2..n]中选出关键字最小的记录,又需要做n-2次比 较。事实上,后面的n-2次比较中,有许多比较可能在前面的n-1次比较中已经做过,但由于前一趟排序时未保留这些比较结果,所以后一趟排序时又重复执行 了这些比较操作。 堆排序可通过树形结构保存部分比较结果,可减少比较次数。